Turbulence Embraced: How Curiosity Took Flight in My Thesis
A Personal Odyssey in Aerospace Engineering
When it came to selecting my thesis, I stood at a crossroads. On one side were topics in NLP and business-related computer science which were safe, familiar, and straightforward. On the other was something entirely different, something that didn’t just promise a degree but a story worth telling. The choice was clear: I wanted a challenge that would test me, teach me, and leave me with a sense of accomplishment far beyond GPA points.
So, I took a leap of faith and ventured into the uncharted skies of aerospace engineering. My thesis topic? Improving aviation through Machine Learning and Deep Learning. A bold intersection of fields, however, it came with its share of turbulence. With no prior experience in mechanical or aerospace engineering, I knew this journey would begin with learning the basics and figuring it out as I went.
I still remember the raised eyebrows and the skeptical looks from others when I told them about my thesis topic. “That’s crazy,” they said. “Why not pick something easier?” But something about the challenge called to me, and in a moment of rebellious clarity, I thought, “Exactly. That’s why I’m doing it.”
In this way, the journey wasn’t just about the final result; it was about the learning process itself, the challenges, the doubts, the failures, and ultimately, the breakthroughs. And while I didn’t know where it would lead, I knew that the reward would be more than just a thesis. It would be an experience that would shape the rest of my career.
If I’ve caught your attention, fasten your seatbelt, because this is only the beginning. Get ready to embark on a journey through the highs and lows of my thesis, a flight filled with innovation, persistence, and a touch of turbulence. Let’s take off!
Turbulent Beginnings: A Search for Usable Data
The Search That Almost Failed
The initial excitement of exploring a new field quickly gave way to frustration. Each dataset I encountered presented unique challenges—missing values for key parameters, irrelevant details, and sources that lacked credibility. Every failed attempt chipped away at my confidence, leaving me to question whether I could even start, let alone complete, this ambitious project. Yet, just when hope seemed to be slipping away, luck intervened. I stumbled upon two datasets that, while limited in scope, offered enough to reignite my determination.
The first dataset, The 50 Most Important Parameters of the 60 Most Used Passenger Aircraft, contained information on aerodynamics, flight mechanics, and engine performance for 60 widely used passenger aircraft. While far from perfect, with missing values needing to be manually verified and filled, it laid the groundwork for understanding the complex relationships between design parameters and performance.
The second dataset, Turbofan Specific Fuel Consumption and Engine Parameters, focused on critical turbofan engine metrics like Overall Pressure Ratio (OPR), Bypass Ratio (BPR), and Specific Fuel Consumption (SFC). Though narrower in scope, it provided reliable and consistent data, saving me the painstaking process of extensive preprocessing. Together, these datasets were limited but invaluable. They were far from ideal, but as the saying goes, “Something is better than nothing.”
With their support, the turbulent start to my thesis began to stabilize, and the promise of meaningful insights came into view. Now, the stage was set for the real work to begin, turning raw data into aviation innovation.
100+ Models, 2 Dataset, and a Lot of Frustration
Into the Unknown: Where Do I Even Begin?
When I first embarked on the journey of building machine learning and deep learning models for my thesis, I was met with an overwhelming sense of uncertainty. Where do I start? What models do I train? What architecture should I even use? These questions loomed large, and without a solid foundation in aerospace engineering, I found myself lost in a maze of parameters, datasets, and algorithms. The limited size of the dataset only added to the complexity as every iteration felt like a shot in the dark, and each attempt seemed to end with a resounding “This isn’t good enough.”
I trained my first model with a naive sense of optimism, only to watch it overfit almost immediately. My supervisor would patiently review the results and then gently point out, “We need to change the parameters. This won’t work.” And so, the cycle began. Each time I modified the architecture, ran performance analytics, and refined the parameters, I hoped I had finally cracked the code. But each time, the outcome was the same, a need to tweak, to reimagine, to start over. What made this process particularly challenging was the sheer number of models I had to train, over 100 architectures, each with subtle variations. From convolutional layers to dropout rates, from activation functions to optimizers, every detail had to be considered, tested, and justified. Some models showed promise at first, only to falter during validation. Others overfit so badly that their predictions were almost laughable. It wasn’t just a test of technical skill; it was a test of patience (which I don’t have much of 😂), resilience, and creativity.
Adding to the frustration was the fact that I was learning as I went. Every failure forced me to dive deeper into understanding the relationships between parameters, the nuances of aerospace metrics, and the quirks of deep learning algorithms. Analytics became my lifeline, I used heatmaps, scatter plots, and correlation matrices to make sense of the chaos. Slowly, patterns began to emerge, but the road to meaningful insights was long and grueling.
Despite the challenges, progress began to take shape. For predicting Specific Fuel Consumption (SFC) during cruise, I focused on parameters like Bypass Ratio (BPR), fan diameter, number of spools, and engine mass. These parameters were identified as critical through correlation analysis and real-world considerations. I developed multiple models, including Convolutional Neural Networks (CNNs), Random Forests, Support Vector Machines (SVMs), and Ensemble Learning techniques. Each model was trained and tested rigorously, with the Random Forest & CNNs emerging as the best performers.
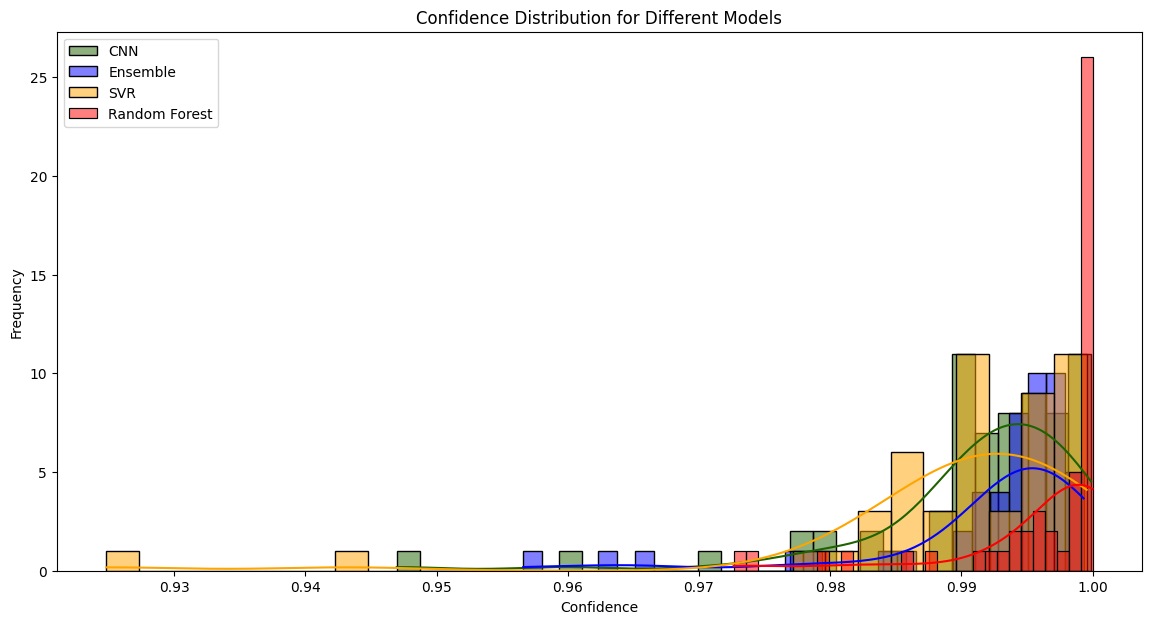
Confidence Distribution for SFC Models.
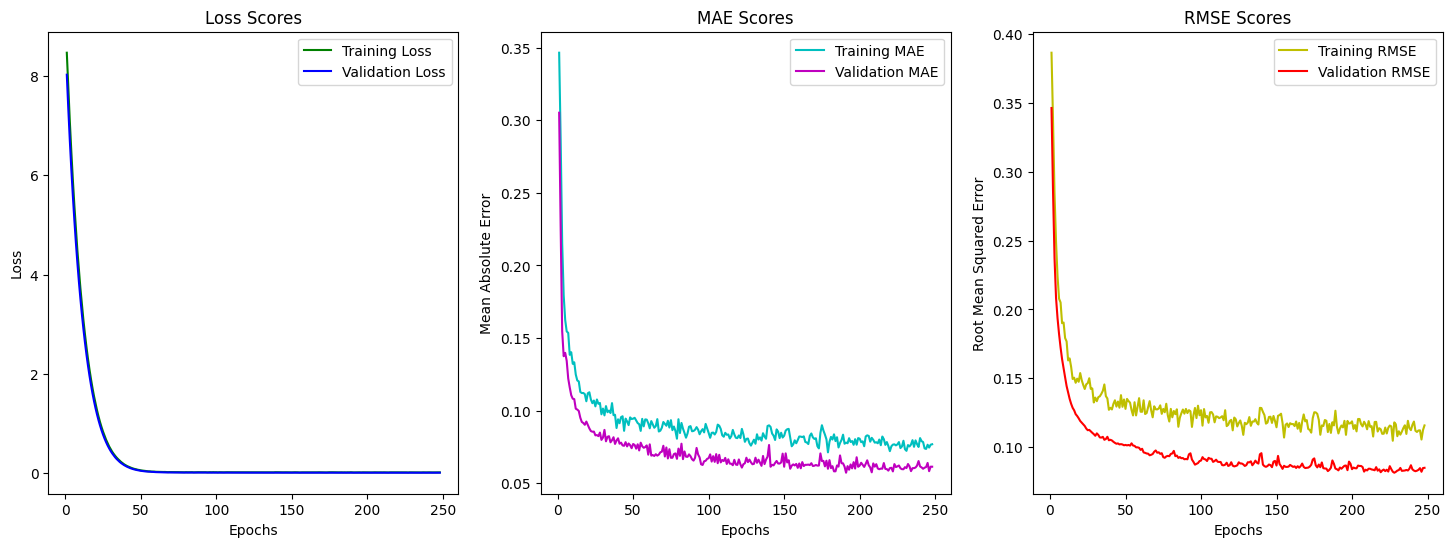
CNN Results for SFC Prediction.
In parallel, I worked on range prediction, using parameters such as maximum payload, usable fuel, and aspect ratio. Principal Component Analysis (PCA) and correlation heatmaps helped identify the most influential variables, reducing noise and improving model accuracy. Both CNNs and Random Forests were trained for this task, with the CNN achieving an impressive R² score of 0.933, closely followed by the Random Forest at 0.904.
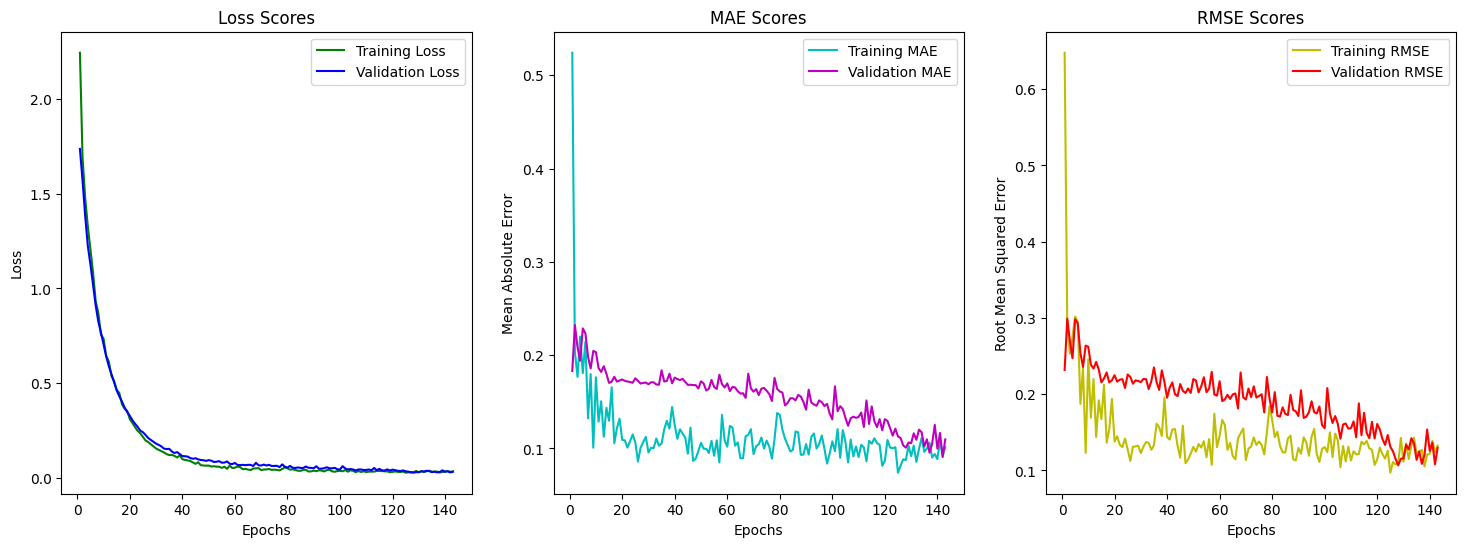
CNN Training Results for Breguet Range Prediction.
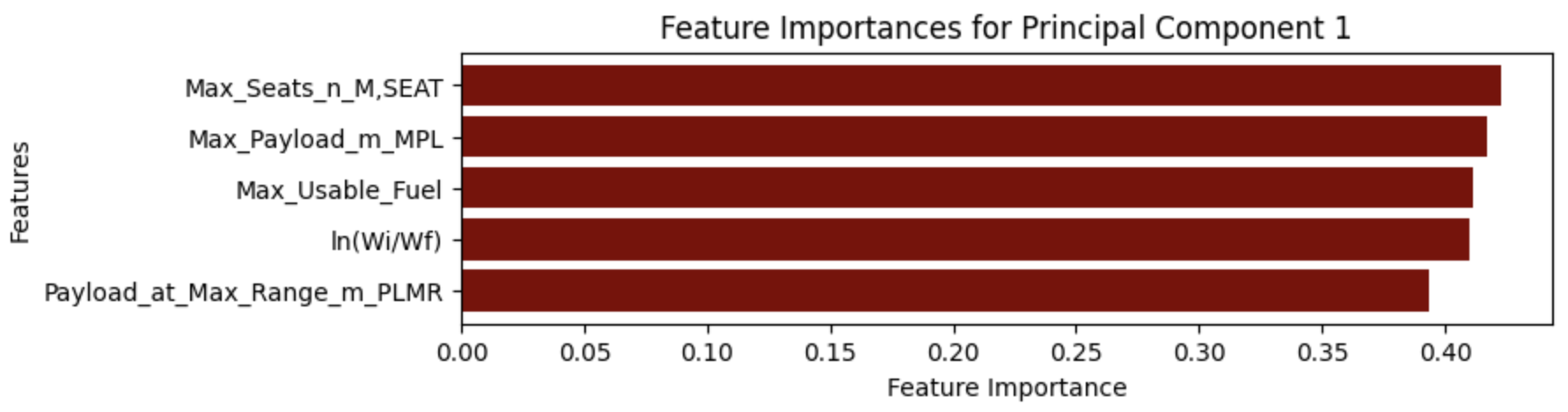
PCA Results Highlighting Key Parameters for Breguet Range.
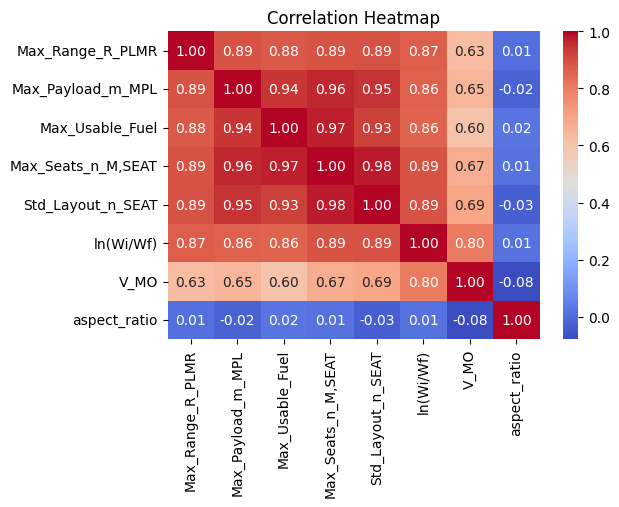
Correlation Heatmap for Key Parameters Influencing Breguet Range.
While developing predictive models was a significant achievement, what made my thesis unique was the focus on explainable AI. It wasn’t enough to merely generate accurate predictions; we wanted to understand the “why” behind those predictions. Which parameters had the most influence? How did they affect the results? And, most importantly, did the model's behavior align with the real-world relationships we observed through analytics?
To achieve this, we combined the predictive power of our models with comprehensive analytics, such as Principal Component Analysis (PCA) and correlation matrices. This dual approach allowed us to evaluate not only the accuracy of our predictions but also their interpretability. These methods ensured that our models not only performed well but also provided insights into the parameters that were most impactful in shaping the outcomes.
Below are examples of parameter importance visualizations, showcasing how different parameters influenced model predictions. These images demonstrate the coherence between our analytics and the model's predictive behaviors. More detailed explanations and results are provided in the thesis document for those who wish to dive deeper.
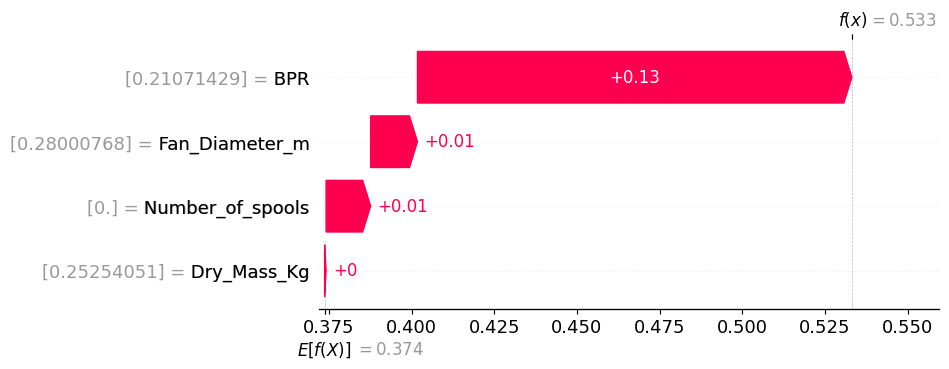
Feature Importance for Specific Fuel Consumption Prediction.
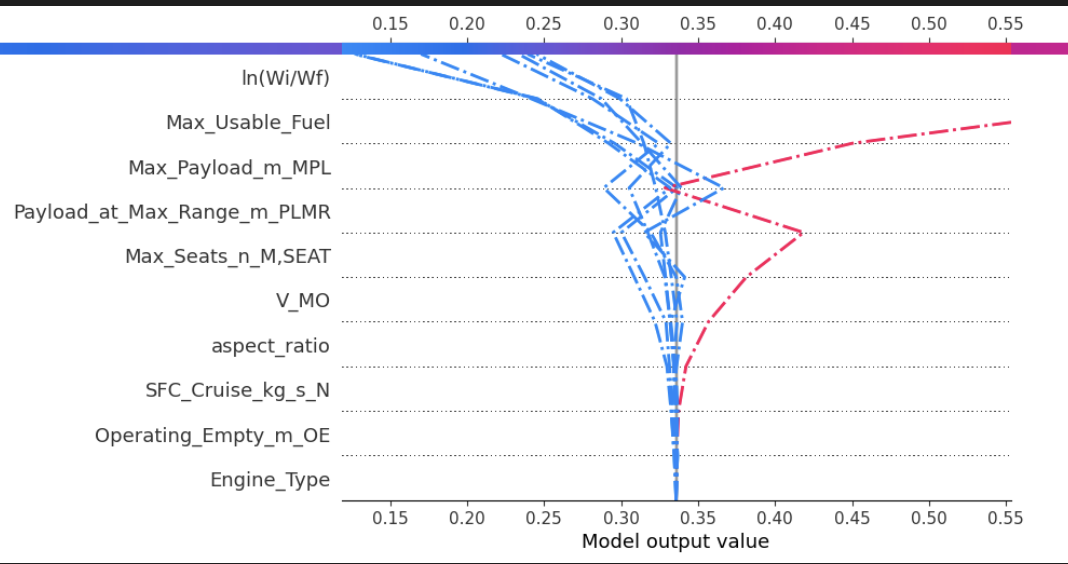
Feature Importance Waterfall for Breguet Range Prediction.
These visualizations highlight the interpretability of our models, offering insights into which parameters were most influential.
The Unexpected Detour: When GenAI Became the Solution
Exploring Uncharted Territories to Meet an Ambitious Goal
When my professor challenged me to go beyond conventional predictions, where input parameters yield fixed outputs, I was caught off guard. It wasn’t just an ambitious request; it was a significant shift in expectations after most of the groundwork had already been laid. Though initially overwhelmed, I saw an opportunity to explore uncharted territories and push the boundaries of what I could achieve.
Determined to find a solution, I started delving deep into the possibilities. That’s when I stumbled upon Generative AI (GenAI). My initial understanding of GenAI was limited to its applications in creating images or art. However, as I read more, I discovered its growing potential in handling tabular data. Generative Adversarial Networks (GANs), especially Conditional Tabular GANs (CTGAN), were gaining traction in fields like healthcare and finance. Aerospace, however, was still largely unexplored.
This was the moment I decided to take a leap of faith. If GANs could generate high-quality synthetic data in other domains, why not use them to address the challenges in aircraft design? The idea was to harness CTGAN’s ability to handle tabular data and create a model capable of bidirectional predictions and data augmentation which will be something truly transformative for our thesis.
Venturing into GenAI wasn’t easy. The theoretical underpinnings of GANs were complex, and adapting them for tabular data required a steep learning curve. The first hurdle was understanding how CTGAN works, a model that trains a generator to produce synthetic data while a discriminator ensures its quality. The second was addressing the challenges posed by our limited dataset. Unlike image datasets with millions of samples, our dataset was small and fragmented, making the task of training a reliable model even more daunting.
But persistence paid off. Through trial and error, hours of research, and countless experiments, we managed to adapt CTGAN for our use case. The model allowed us to predict missing parameters from existing ones and even generate synthetic data to augment our limited dataset. While the results weren’t perfect, because of the limitations of our data, they marked a significant step forward in exploring the potential of GenAI in aerospace engineering.
Below is a visualization of the CTGAN output, demonstrating the model's ability to generate synthetic data and predict parameters based on limited inputs. While the journey was filled with challenges, this result represents a pioneering effort in applying Generative AI to aircraft design.
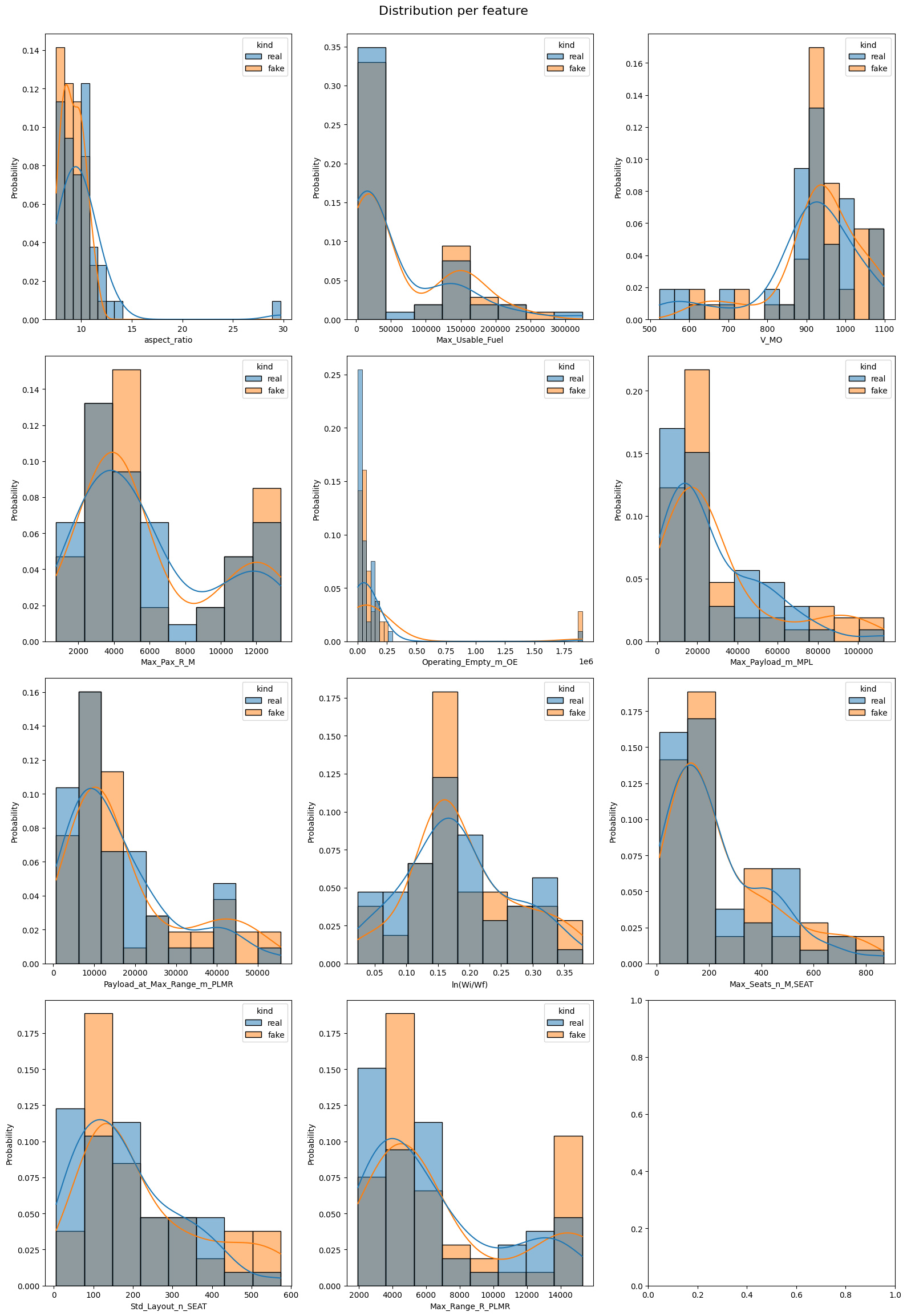
Distribution per feature: Comparison of real and synthetic data generated by CTGAN.
Preparing for Landing: Wrapping Up the Journey
Introducing CTGAN into our thesis was more than just a technical accomplishment; it was a leap into the unknown. By exploring the intersection of Generative AI and aerospace engineering, we ventured into a field that remains largely unexplored. While the results were far from perfect, they proved that even in the face of limited data and uncharted methods, innovation is possible. This experience not only broadened the scope of our thesis but also underscored the transformative potential of Generative AI in redefining aircraft design.
I hope you enjoyed this flight through the highs and lows of my thesis. As we prepare to land, let’s reflect on the journey filled with turbulence, discovery, and the thrill of exploration. Thank you for coming along on this adventure. The runway ahead may mark the end of this journey, but it’s also the beginning of new possibilities in aviation and beyond.