But Do You Have Experience in NLP? A Question That Sparked a Journey
It was sometime between April and May of 2023 when a colleague, a seasoned data scientist, casually asked, "But do you have experience in Natural Language Processing?" I’d built machine learning models, tackled various data challenges, but NLP? That was uncharted territory. Intrigued by his work and inspired to expand my skillset, I decided to dive into the world of NLP and Large Language Models (LLMs). That semester, I committed myself fully, setting out to unravel the concept behind "Attention is All You Need" (no, not the song by Charlie Puth!). But first, I needed to grasp the magic of “Attention” itself—and before that, figure out how to actually *talk* to machines.
To truly master NLP, I realized I’d need to dig into the fundamentals—not just the technical bits, but the practical, hands-on side of it, too. What started as simple curiosity turned into a full-blown journey, sparking project after project: from extracting insights from complex contracts and crafting smarter recommendation systems, to building models that could assist public services and even translate languages. Let’s hope I’ve grabbed your *attention* by now! Below are some of my projects in NLP and LLM.
FastAPI, LangChain, Docker, and One Extremely Lucky Human: A Chatbot’s Survival Story
"Why Not Build a Chatbot?" A Statement That Ruined My Week
It all started when LLMs became the hottest trend in tech. Everyone was either building a chatbot, deploying a chatbot, or asking me if I had built one. Everyone was asking me if I had worked with LLMs. And, well... I had, however, it was back in 2023. I worked on an LLM-powered chatbot for the Berlin City Administration, answering citizen queries (because nothing says "innovation" like government bureaucracy needing AI assistance). But back then, downloading models was a nightmare. Importing them into a server? Nearly impossible. And LangChain? It was still in its awkward teenage phase, constantly changing, breaking, and leaving us wondering what went wrong. So, naturally, I decided to revisit this domain thinking "How hard could it be now?"
So I wanted to build a chatbot for my portfolio website that could answer questions about my experience, projects, and skills. But as soon as I sat down, reality hit me like a wrecking ball. I never hit so hard in love. Oh wait, let's not get distracted. As I was saying, where do I even start? How do I structure the backend? How do I make it work without breaking my laptop in half? I had some LLM experience, but after months away from the field, it felt like I was starting from scratch. So, I did what any self-respecting developer would do... I Googled the hell out of it.
Step one was figuring out where to store my data. I decided to throw my entire work experience into a JSON file, because why not? It’s clean, structured, and doesn’t judge me for copy-pasting the same job description five times. Then came LangChain, and wow. The last time I used it, it was still figuring itself out. Now? It has a library for EVERYTHING. Need to split text? There's a function. Need embeddings? There's a function. Need it to bring you coffee? Probably a function for that too.
Next came embeddings. The last time I worked with them, we had to store everything in RAM (yes, really), which was an absolute disaster for scalability. But now, we had proper embedding models, including OpenAI’s and Hugging Face’s. Naturally, I tried Hugging Face’s embeddings first because I love open-source tools. But after some testing, I had to admit the painful truth: OpenAI’s embeddings were simply better for my use case. So, I swallowed my pride, threw some API calls at OpenAI, and moved on.
I then faced the heart of RAG: vector databases. If embeddings were the blood, vector databases were the circulatory system. After some research (aka deep-diving into Reddit threads), I decided on ChromaDB for storing and retrieving embeddings. It worked beautifully, and after some trial and error, I figured out the best retrieval strategy (k=2 or k=5? k=3.14 for fun?) to ensure my chatbot returned relevant answers without making things up.
With my data prepped and stored, I moved on to the actual model. I had two options: I could either run an LLM locally (which would turn my laptop into a glorified space heater) or use an API. Given my previous struggles with model downloads and hardware limitations, I went with Hugging Face’s API and picked DeepSeek 70B as my model of choice. It worked well, but I quickly ran into a new problem: memory and prompting. The chatbot had the memory of a goldfish, forgetting what was said just two messages ago. And if I didn’t phrase the prompt correctly, it would either refuse to answer anything or start hallucinating random facts. I spent hours tweaking the prompt, balancing between allowing it to answer general questions and ensuring it stayed within the context of my portfolio. After a lot of trial and error, I finally got it to a point where it could respond naturally while staying relevant.
Just when I thought I was done, backend-frontend integration hit me like a truck. I used FastAPI for the backend and a simple HTML/CSS/JavaScript frontend, thinking it would be a quick connection. It was not. Sometimes the backend worked, but the frontend didn’t. Other times, the frontend worked, but the chatbot wouldn't respond. I spent 1.5 days debugging, constantly switching between console logs and API responses, wondering why I even started this project in the first place. At one point, I was this close to smashing my laptop. But finally, after a ridiculous amount of trial and error, the chatbot worked.
And then came Docker Hell. Whoever says containerization is easy, there’s a special place in hell for you. I had worked with Docker before, and guess what? I never liked it. But yeah, here we go again. The theory was simple: Dockerize the backend, Dockerize the frontend, connect them, and boom, everything works. HAHAHA. Next joke, please. At first, things seemed fine. Backend? Built successfully. No errors, no warnings, and life was good. Frontend? Built successfully. Okay, we’re cruising now. But then, the moment I tried to run the chatbot inside the containers? Disaster. The frontend was fine, the backend was running, but the chatbot just outright refused to answer requests. Every time I sent a query, I got authentication errors. API requests were failing left and right. I checked the logs, restarted the containers, and even rebuilt everything from scratch, but nothing changed. At this point, I was questioning all my life choices, wondering if I should’ve chosen some other field instead.
I was sitting there for hours, staring at my terminal like it personally betrayed me. It made no sense. The API key was right there. The .env file was in place. What was wrong? Then, a friend came over to pick up a speaker I had borrowed. We chatted for a bit, she grabbed the speaker, and as soon as she left… 💡 It hit me like a lightning bolt. The environment variables had accidentally changed. Somewhere along the way, probably during one of my "let’s rebuild everything and hope for the best" moments, I had messed up the .env file. The Hugging Face API key was either missing or incorrectly loaded inside the container. That’s why the chatbot kept refusing my requests, it wasn’t actually authenticated.
One quick fix, a restart, and just like that… it worked. Every request went through perfectly. I just sat there, staring at my screen, feeling both victorious and utterly stupid at the same time. So now I have two theories: Either I was so deep in debugging hell that my brain had completely shut down, refusing to process basic logic, or my friend was some kind of cosmic force of good luck. Like a walking, talking Stack Overflow answer disguised as a human. Was it pure coincidence that the moment she walked in, I was drowning in Docker's misery, and the moment she left, everything suddenly clicked? Or was she unknowingly channeling some divine debugging energy into my apartment? Honestly, at this point, I’m not ruling anything out. Next time my code breaks or my life, for that matter, I’m calling her over for coffee. Who knows? Maybe she’ll fix both.
Either way, the chatbot was finally fully Dockerized, running smoothly, and I was ready to deploy. Until… I remembered something very very important: GitHub Pages doesn’t support dynamic websites. Yep. After all that work, I couldn’t even deploy it on GitHub. My chatbot required a backend, API calls, and a vector database, all things GitHub Pages simply does not support. At this point, I just stared at my screen, took a deep breath, and told myself, I’ll deal with deployment later.
This project was a rollercoaster of emotions, from rediscovering LLMs, to struggling with Docker, to wasting hours over a single missing environment variable. But despite the pain, frustration, and near-laptop-smashing moments, I learned a ton. Now, I have a fully functional, Dockerized chatbot, ready to be deployed somewhere that actually supports it.
And as for my friend? If I ever start a software company, she’s getting an honorary CTO position—Chief Troubleshooting Officer.
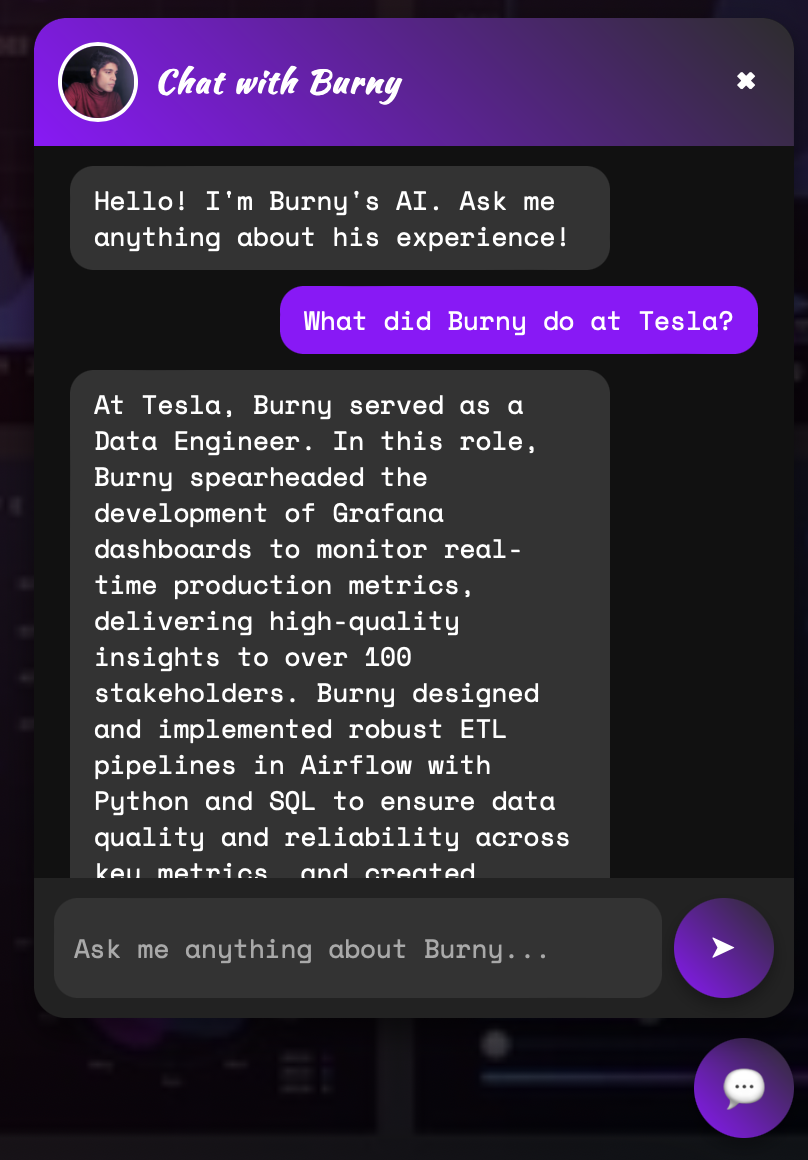
Website Chatbot
The Clearlea Challege
Since no one is working on the technical side, let’s actually develop the model,” I said… forgetting we had only 8 hours!
One of my university marketing courses took us to a hackathon where we faced a unique challenge from a company called Clearlea. The company's mission was straightforward yet impactful: to take users' contract documents, analyze them, and provide clear answers on a user-friendly dashboard. Our task? To improve the user experience for their app. The founder was clearly hoping for some technical insights (or at least that’s what I thought). But with a course full of non-technical students, it seemed unlikely that he’d get what he was looking for. Meanwhile, I couldn’t help but think, “If I do this well, it’ll look fantastic on my GitHub!” Driven by that thought, I dived into the technical side, even when the founder remarked, “Wow, you look like one of the technical ones.” While others pitched general app improvements, I presented a different view: sometimes, customers don’t know exactly what they want. As Henry Ford famously said, “If I had asked people what they wanted, they would have said faster horses.”
And so, we got to work developing a model for Clearlea. Despite only having 8 hours, we managed to create a functional prototype. Our team tackled challenges like sourcing a relevant dataset for contract law—a task easier said than done. Without readily available data, we identified common parameters in contract laws (like start date, rent, and interest rate) and generated our own dataset using ChatGPT. For model selection, we initially considered LLaMA and Gemini but faced regional limitations. Ultimately, we utilized LLaMA3 70b for reliable insights and Mixtral 8x7b, a model Clearlea was already using. Our pipeline handled document processing, question answering, and JSON-based result storage, enabling us to assess the model's performance. To evaluate output quality, we compared answers from both models against ChatGPT benchmarks and used manual scoring to validate accuracy. This collaborative effort with Clearlea’s team allowed us to deliver a refined, prototype solution within our tight timeline, offering meaningful enhancements to the user experience. Our pipeline was designed to handle document processing, question answering, and results storage. I focused on setting up APIs and automating the pipeline to ensure seamless document analysis and result storage in JSON format, which allowed us to review and improve the model’s accuracy. To evaluate the models, we manually assessed their responses using ChatGPT as a benchmark, scoring each answer to refine our approach.
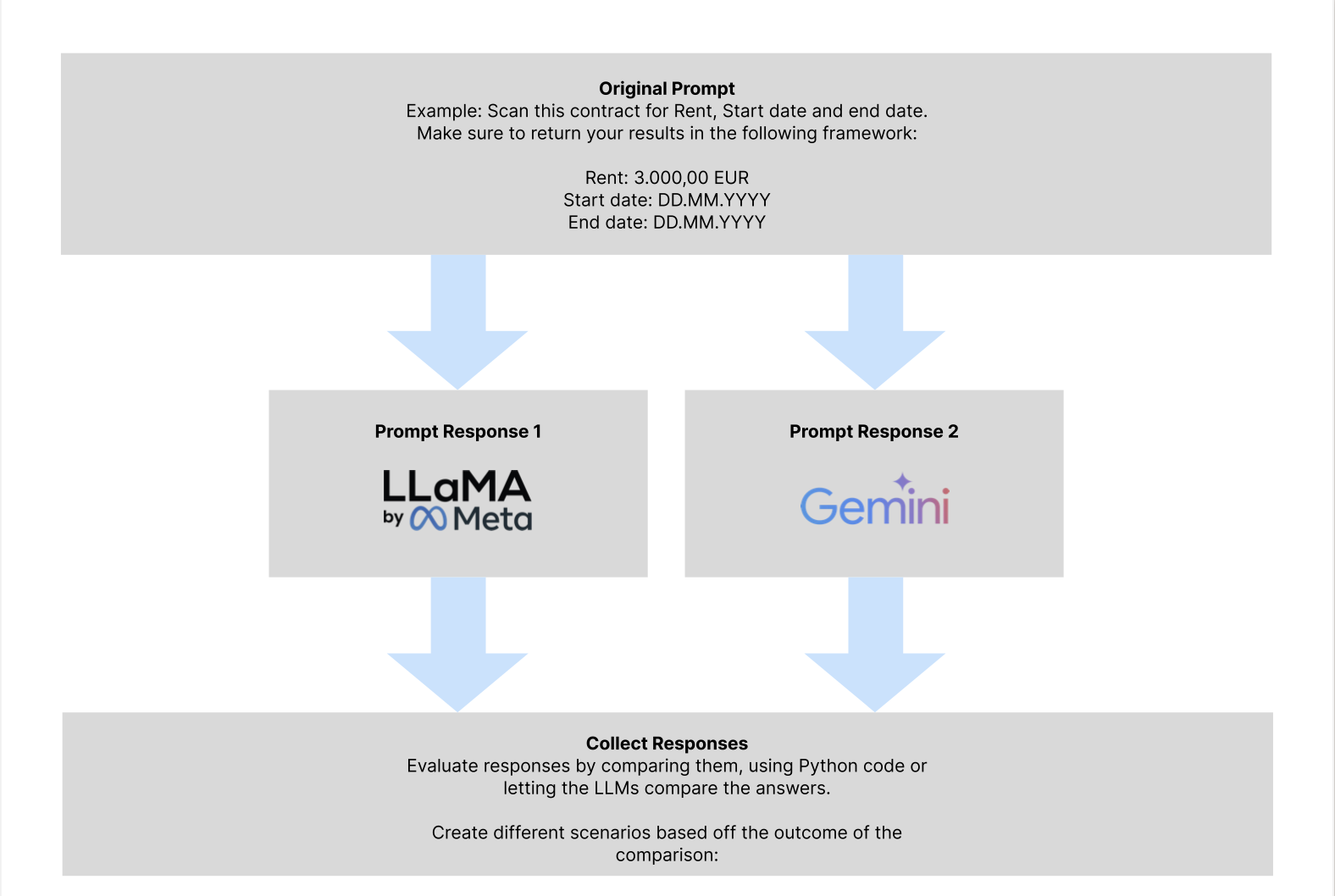
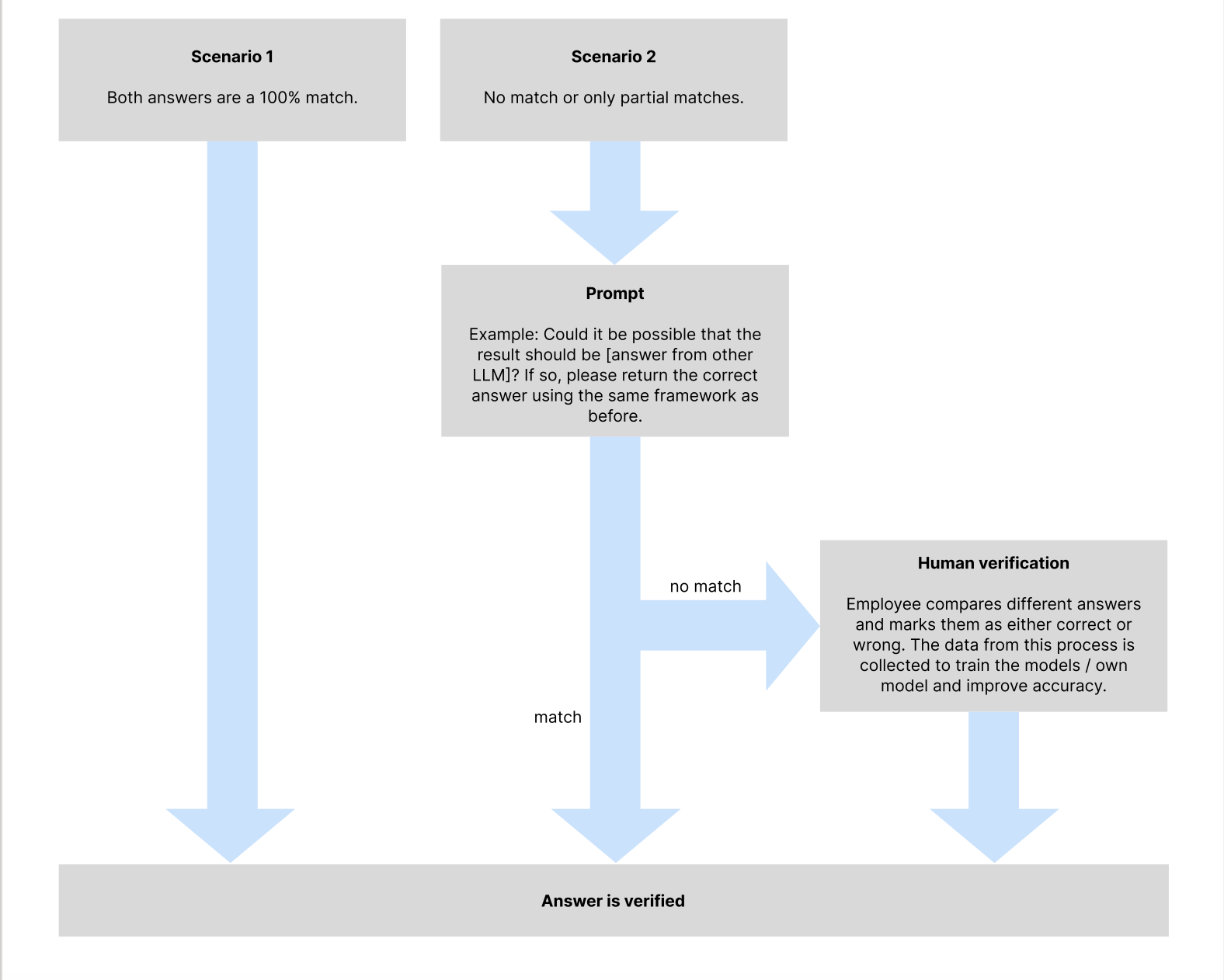
Figure: Data Pipeline & Model Architecture.
In the end, our team’s collaboration, along with insights from Clearlea’s partners, helped us overcome technical challenges and produce a working prototype in record time. It was an experience that strengthened my technical skills and highlighted the importance of teamwork and problem-solving.
View on GitHubChatbot Bobbi
Let’s Make This Chatbot Great Again!
The City of Berlin contains a Chatbot Bobbi to assist users in finding information about city services. However, due to its limitations in answering complex and diverse questions, our team set out to enhance its capabilities using Large Language Models (LLMs). By integrating models such as Chatgpt 3.5, LLaMA, Zicklein, and RWKV alongside a backend database, we aimed to build a chatbot that could provide more accurate, context-sensitive responses. Our architecture, as shown in the image below, includes a user interface built with Next.js, a FastAPI server, and an Apache SolR knowledge base that stores reliable information about Berlin’s services. When a user submits a query, the system checks the knowledge base for relevant information and uses a prompt generator to formulate questions for the LLMs. The responses from the selected LLMs are returned to the user, who can provide feedback through a star rating stored in an SQLite database. This feedback loop helps us understand the effectiveness of each model.
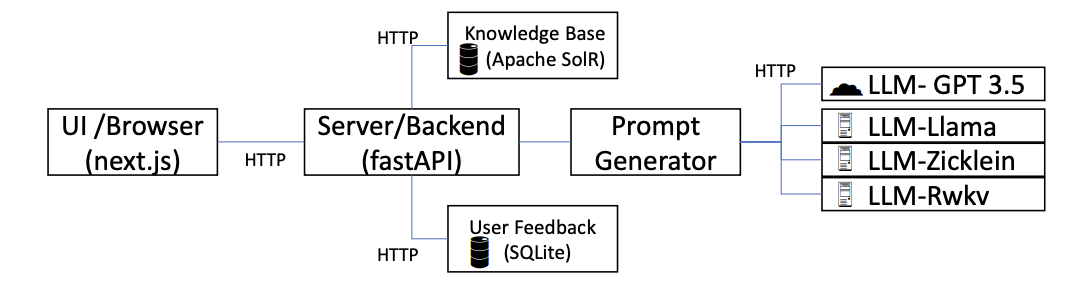
Figure: System Architecture of the Enhanced Chatbot Bobbi
An example of a conversation is shown below. Some challenges we faced included handling hallucinations (when models provide plausible but incorrect answers) and ensuring quick response times, particularly for the locally deployed models. Despite these, our approach has shown promising results, with improved response accuracy and user satisfaction compared to the original Chatbot Bobbi.
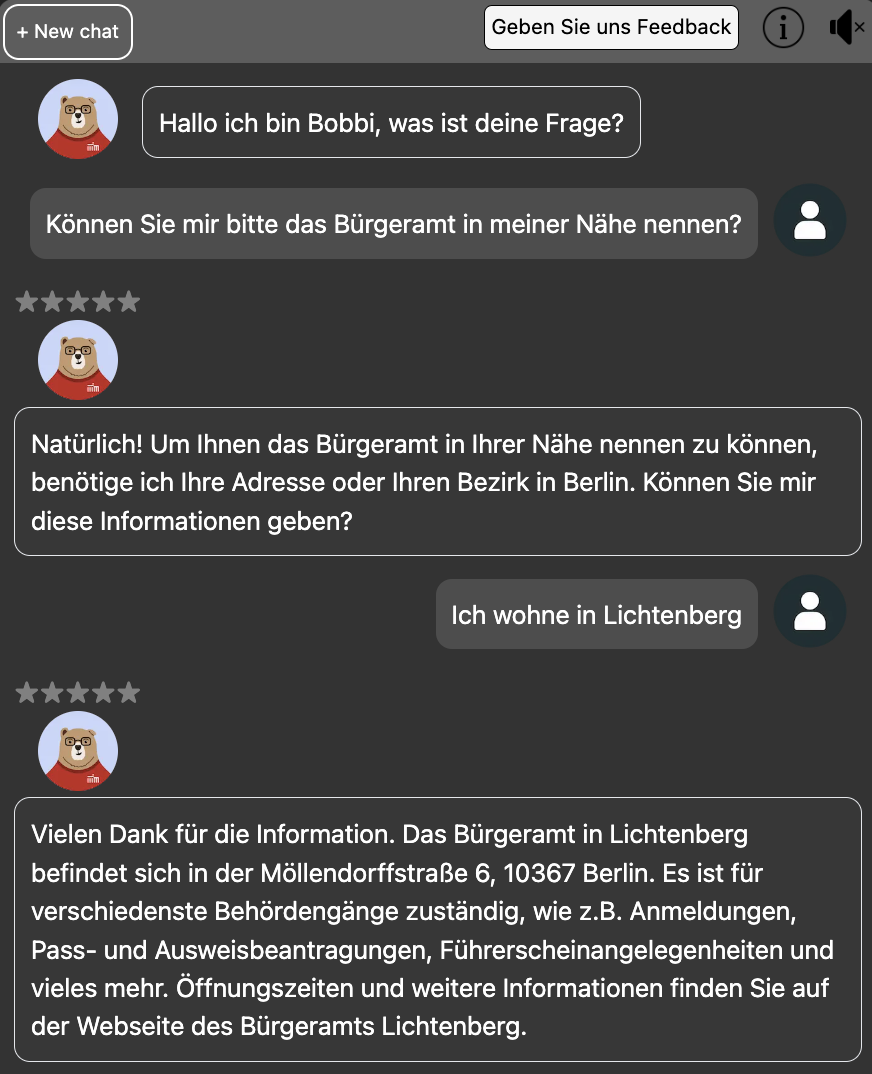
Figure: Example of Enhanced Chatbot Bobbi Interaction
Transform Your Watchlist: A Smart, Sequence-Savvy Recommender
Your Next Favorite Movie Isn’t Random – It’s Science!
Every movie you watch, every title you skip, and every rating you give tells a story – not just about what you like, but how your preferences evolve over time. Traditional recommendation systems often ignore this sequence, treating your history like a static checklist. But preferences are dynamic, like a moving painting, constantly reshaping.
Enter the Behavior Sequence Transformer, a system that listens to the rhythm of your choices. It doesn’t just suggest movies; it weaves together patterns, detects shifts in interests, and evolves with you. Using transformers – the backbone of modern AI – we created a system that sees beyond isolated data points. It captures the context, the order, and the why behind your preferences.
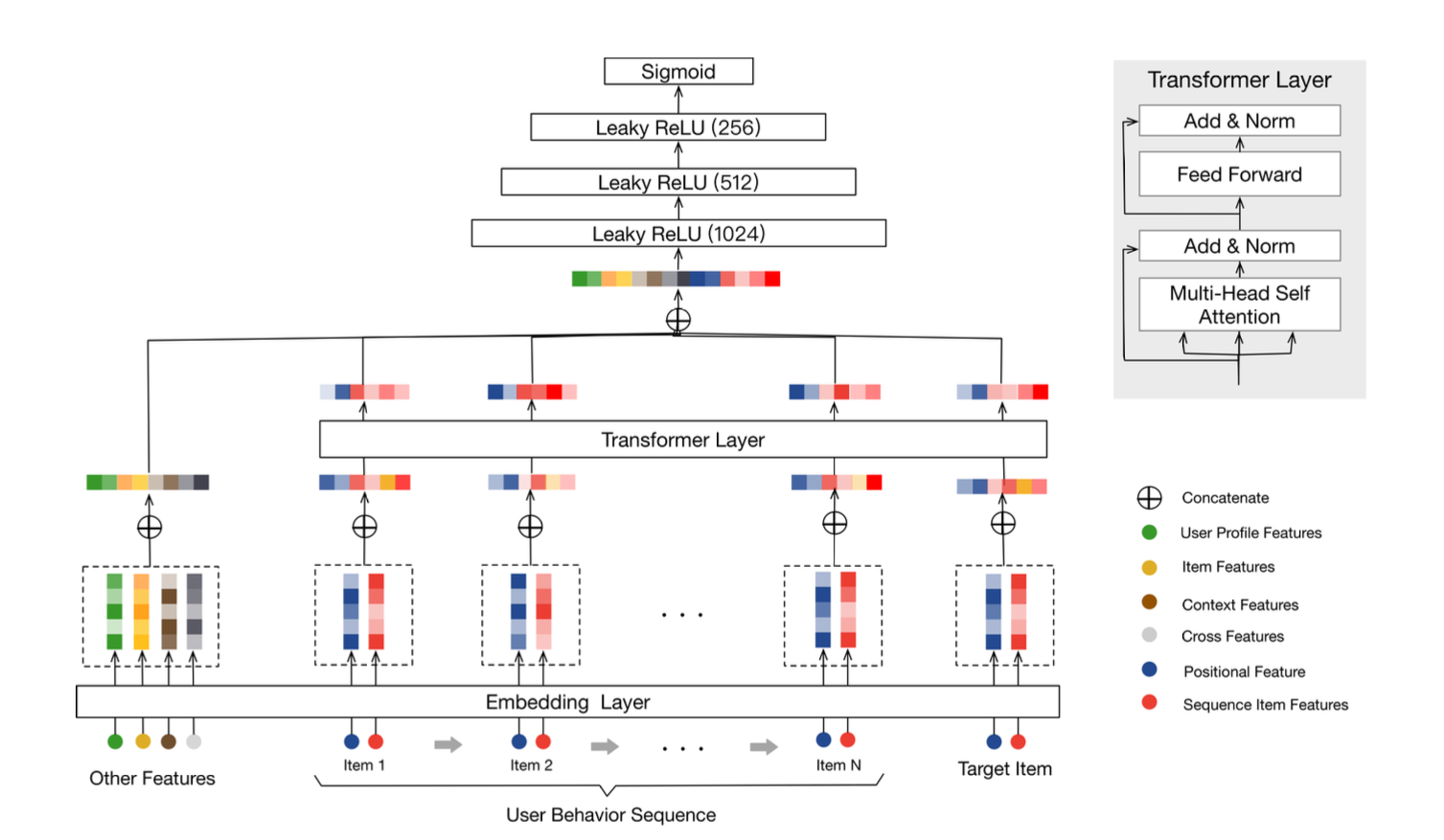
Architecture of the Behavior Sequence Transformer.
The architecture combines contextual user data (like movie genres, ratings, and user profiles) with the self-attention mechanisms of transformers. Every sequence is a story, and every attention layer learns its meaning. By understanding these interactions, the system ensures that your next recommendation feels less like a guess and more like a perfectly-timed suggestion.
Results
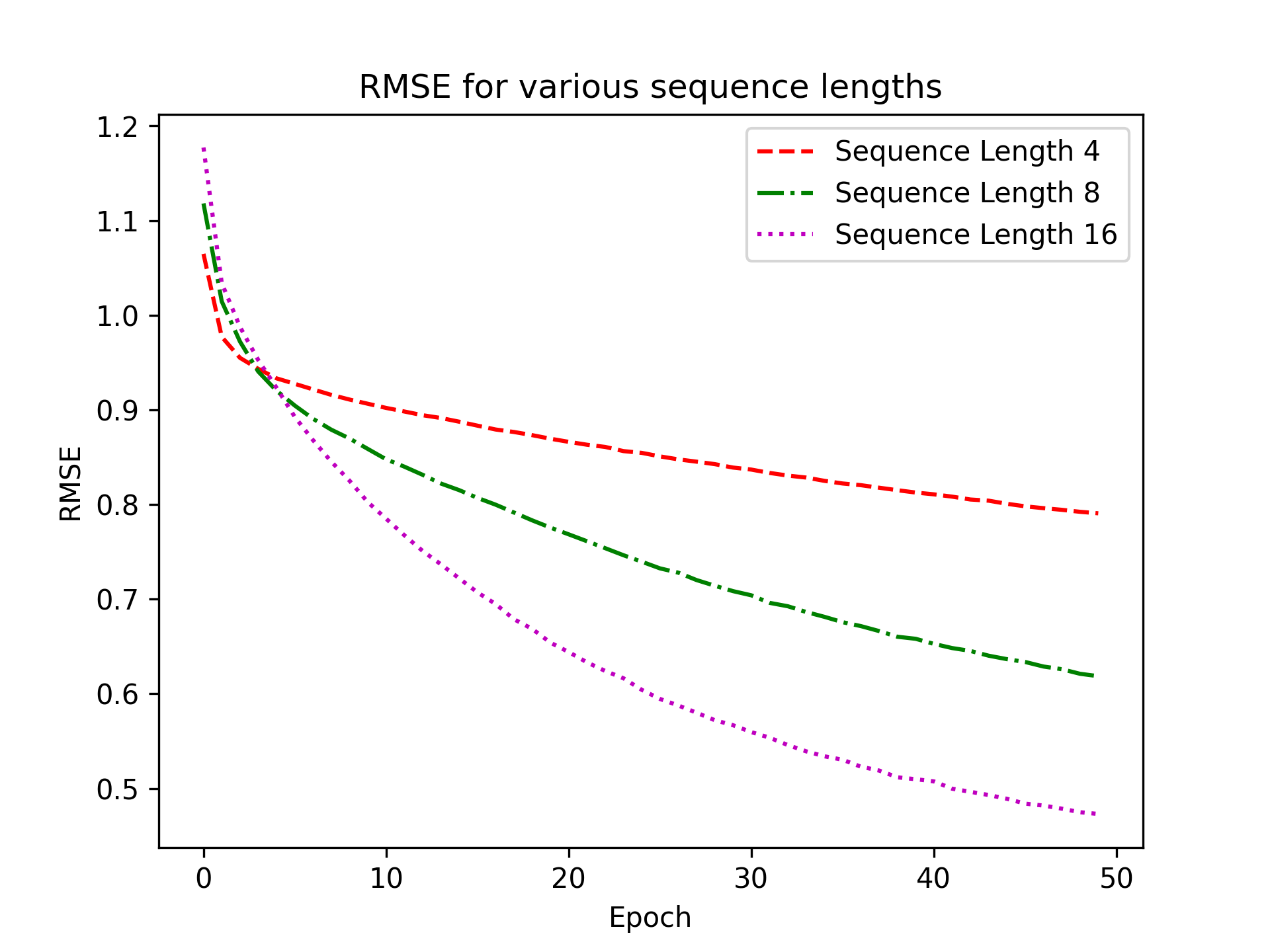
Impact of sequence length
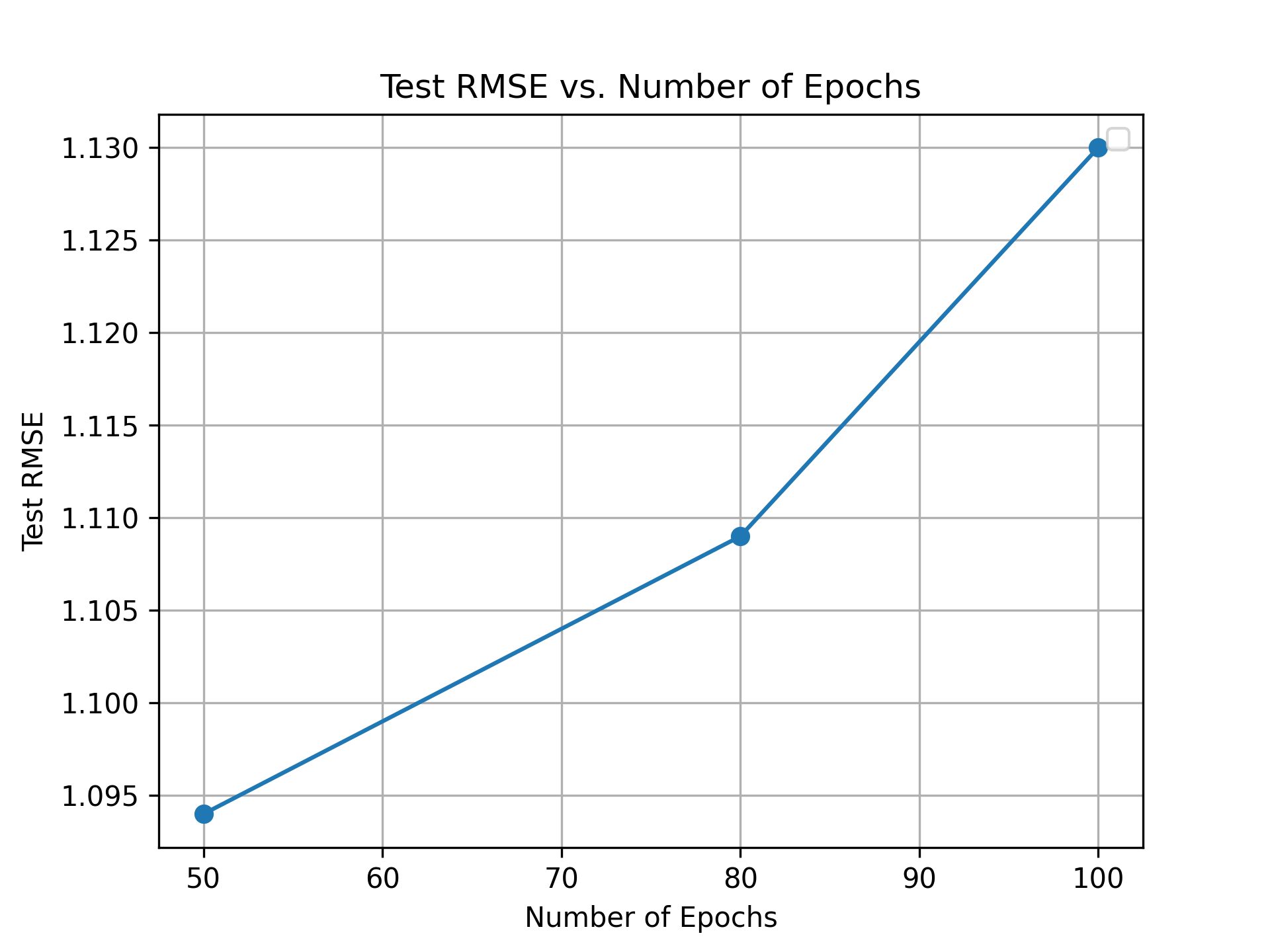
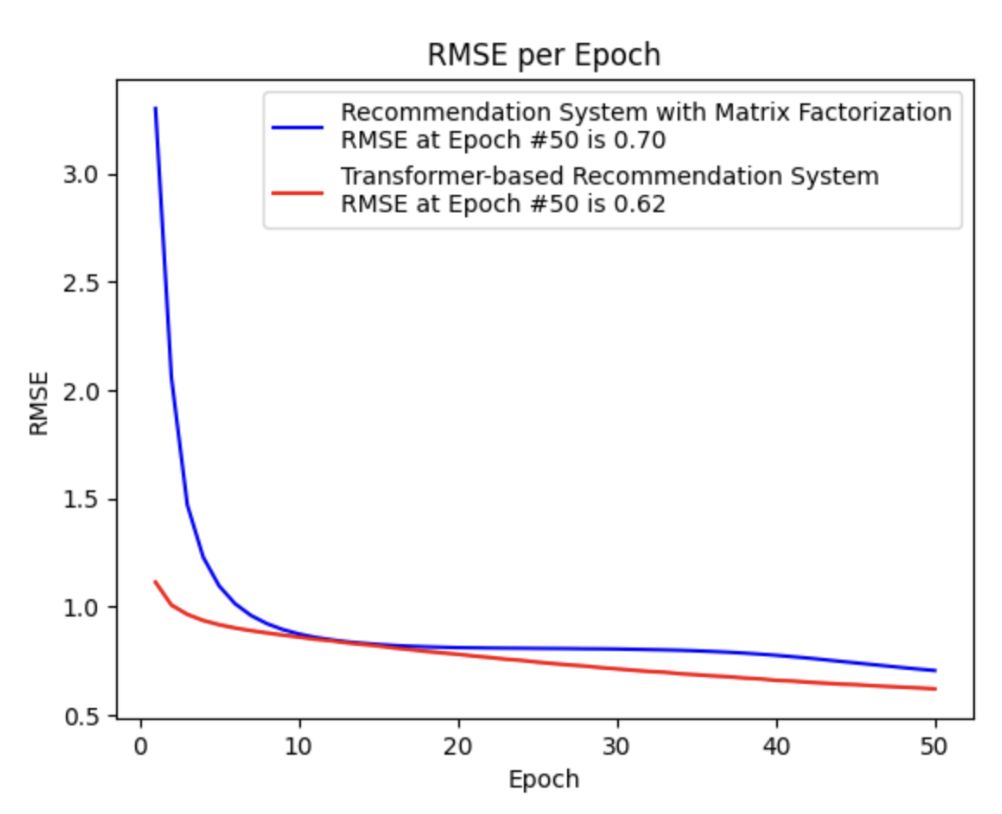
These results highlight the transformational power of our model. As seen in the sequence length analysis, the system carefully balances its ability to learn from longer histories without overfitting. By optimizing the number of training epochs, we ensured the model reached peak performance while maintaining computational efficiency. The comparison with traditional systems showcases the significance of sequence-aware modeling, solidifying our approach as a game-changer in recommendation systems.
Imagine a system that doesn’t just predict what you might want to watch, but grows alongside you, adapting to your ever-changing tastes.
View on GitHubFrom Cyrillic to English with a Neural Spin!
Building a Translator that Understands the Story Behind Every Sentence
Translating languages isn’t just about replacing words—it’s about understanding their essence. Using the European Parliament Proceedings Parallel Corpus, we trained a neural machine translation model capable of translating between English and Bulgarian. This task presented unique challenges, from Cyrillic alphabet handling to capturing complex syntax. Here’s how we tackled it.
Preprocessing played a pivotal role in preparing the dataset for neural learning. We tokenized sentences, normalized case, and leveraged pre-trained word embeddings—GloVe for English and FastText for Bulgarian. These embeddings transformed words into dense semantic vectors, capturing both meaning and context.
We experimented with various model architectures, including standard Recurrent Neural Networks (RNNs) and an improved attention-based RNN model. The RNN model used GloVe embeddings for English and FastText for Bulgarian, transforming words into dense vectors that capture semantic relationships. By incorporating attention mechanisms, we achieved a substantial improvement in translation accuracy, especially on longer sentences where the attention model could focus on specific parts of the sequence.
Model Architectures
RNN-Based Seq2Seq Model
def seq2seq_model(input_vocab_size, output_vocab_size, encoder_embedding_matrix, decoder_embedding_matrix,
embedding_dim=300, max_length=25, hidden_units=128, change_targets=False):
if not change_targets: # English to Bulgarian
encoder_inputs = Input(shape=(max_length,))
encoder_embedding = Embedding(input_vocab_size, embedding_dim, weights=[encoder_embedding_matrix],
input_length=max_length, mask_zero=True)(encoder_inputs)
encoder_lstm = LSTM(hidden_units)(encoder_embedding)
decoder_inputs = Input(shape=(None,))
decoder_embedding = Embedding(output_vocab_size, embedding_dim, weights=[decoder_embedding_matrix])(decoder_inputs)
decoder_lstm = LSTM(hidden_units, return_sequences=True)(decoder_embedding)
decoder_outputs = Dense(output_vocab_size, activation='softmax')(decoder_lstm)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
else: # Bulgarian to English
...
return model
Attention-Based Seq2Seq Model
def seq2seq_attention(input_vocab_size, output_vocab_size, encoder_embedding_matrix, decoder_embedding_matrix,
embedding_dim=300, max_length=25, hidden_units=128, dropout_rate=0.2):
encoder_inputs = Input(shape=(max_length,))
encoder_embedding = Embedding(input_vocab_size, embedding_dim, weights=[encoder_embedding_matrix],
input_length=max_length, mask_zero=True)(encoder_inputs)
encoder_lstm = LSTM(hidden_units, return_sequences=True)(encoder_embedding)
encoder_lstm = Dropout(dropout_rate)(encoder_lstm)
decoder_inputs = Input(shape=(None,))
decoder_embedding = Embedding(output_vocab_size, embedding_dim, weights=[decoder_embedding_matrix])(decoder_inputs)
decoder_lstm = LSTM(hidden_units, return_sequences=True)(decoder_embedding)
decoder_lstm = Dropout(dropout_rate)(decoder_lstm)
cross_attention = CrossAttention(units=hidden_units)
decoder_attention = cross_attention(decoder_lstm, encoder_lstm)
decoder_outputs = Dense(output_vocab_size, activation='softmax')(decoder_attention)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
return model
The final results showed that the attention model outperformed standard RNNs, delivering significantly higher BLEU and METEOR scores. However, due to memory constraints, we evaluated the model on a limited sample, but it showed promising results for future expansion. This project highlighted the power of attention in neural machine translation, allowing our model to translate effectively between Bulgarian and English.
View on GitHubDecoding Financial Sentiment: A Deep Dive into Market Mood
Turning Headlines into Insights with NLP-Powered Sentiment Analysis
Markets are driven by emotion, and headlines are often their loudest echoes. This project aimed to unlock the sentiment hidden in financial news—transforming headlines into actionable insights that could help investors gauge market mood and make informed decisions.
Financial headlines aren’t just text; they’re a treasure trove of nuance, statistics, and implications. Our first challenge was taming this raw data, which came with its quirks—short sentences, symbol-heavy phrasing, and a noticeable imbalance in sentiment classes where neutral headlines dominated. To address these challenges, we implemented a sophisticated preprocessing pipeline that included steps like lowercasing, symbol replacement, lemmatization, and tokenization. These transformations turned noisy data into a structured format, laying the foundation for effective analysis.
To classify sentiment, we tested models including Naïve Bayes, Feed-Forward Neural Networks (FFN), and Random Forest. Among these, Random Forest emerged as the top performer, achieving an impressive F1-score of 0.91. Its ability to handle the complexities of balanced data highlighted its suitability for this task, while oversampling techniques significantly improved the performance of all models.
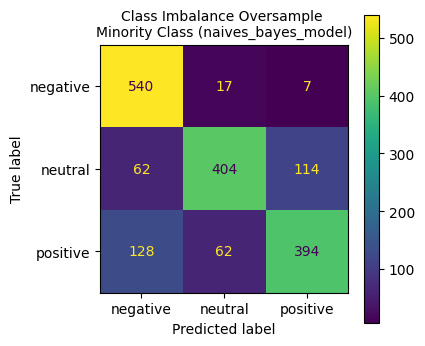
Naïve Bayes classifier results with oversampled minority class.
.png)
Random Forest classifier results with oversampled minority class.
This project demonstrated how NLP techniques can decode market sentiment, turning financial headlines into valuable insights. By applying the right preprocessing, feature engineering, and modeling strategies, we showcased the potential of data-driven decision-making in finance.
View on GitHub